Abstraction means to focus on essential features of an element or object in OOP, ignoring its extraneous or accidental properties.
The essential features are relative to the context in which the object is being used.
Grady Booch has defined Abstraction as follows:
"An Abstraction denotes the essential characteristics of an object that distinguish it from other kind of objects and thus, Provides crisply defined conceptual boundaries, relative to prospective to viewer".
for example:
when a class student is designed the attributes student-id, Name, Course and Address are included while characteristics like pulse-rate and size of a shoe are eliminated , Since they are irrelevant in the Prospective of educational institution.
Saturday, December 31, 2016
Friday, December 30, 2016
Class (Basic concept of OOAD)
A class represents a collection of objects having same characteristics properties that exhibit common behavior. It gives the blue print or description of an object that can be created from it. creation of an object is an instance of a class.
The constitution of a class are:
- A set of attributes for the object that are to be instantiated from the class. Generally different objects of a class have some difference in values of the attributes . attributes are often refereed as a class data.
- A set of operations that shows the behavior of the objects of the class. operations are also refereed as functions or methods.
Let us consider a simple class, circle that represents the geometrical figure circle in 2 dimensional space.
some of its operations can be defined as findArea(): method to calculate area.
scale(): method to increase or decrease the radius.
During Instant-ion, values are assigned for at least some of the attributes.
if we create an object my_circle, we can assign values like x=2,y=3 and r=4, to depict its state .
now if the operation scale() is performed on my_cycle with a scaling factor 2 , the value of r will become 8.
This operation brings a change in the state of my_cycle. ie,the object has exhibited certain behavior.
Objects (Basic Concepts of OOAD)
An object is a real word element in an object oriented environment that may have a physical or a conceptual existence.
Objects can be modeled according to the needs of the application. An Object may have physical existence like a customer, a car etc. or an intangible conceptual existence like a project, a process etc.
Each Object has:
Objects can be modeled according to the needs of the application. An Object may have physical existence like a customer, a car etc. or an intangible conceptual existence like a project, a process etc.
Each Object has:
- Identity that distinguish it from other objects in the system.
- state that determines the characteristic properties that the object holds.
OOP(Introduction to OOAD)
It refers to a type of Computer Programming in which Programmers define not only the data type of data structure, but also the type of Operations (functions)that can be applied to data structure.
In this way the data structure becomes object that includes both data and functions. In addition, Programmers can create relationship between One Object and another Object.
Object Oriented Programming is a programming Paradigm based upon object (having both data and methods) that advantages of module and re usability.
Objects,which are usually instances of classes, are used to interact with one another to design application and computer programs.
Grady booch
Grady booch has defined Object Oriented Programing as "A method of Implementing in which Programs are Organized as co-operative collection of objects, each of which represents an instance of some Hierarchy of classes united via Inheritance relationship."
In this way the data structure becomes object that includes both data and functions. In addition, Programmers can create relationship between One Object and another Object.
Object Oriented Programming is a programming Paradigm based upon object (having both data and methods) that advantages of module and re usability.
Objects,which are usually instances of classes, are used to interact with one another to design application and computer programs.
Grady booch
Grady booch has defined Object Oriented Programing as "A method of Implementing in which Programs are Organized as co-operative collection of objects, each of which represents an instance of some Hierarchy of classes united via Inheritance relationship."
OOD (Introduction to OOAD)
Design emphasizes a conceptual solution that fulfill the requirement rather than its implementation.
for example: a description of database schema and software object.
Ultimately design can be implemented, Design encompasses the discipline approach. we use to invert a solution for some problem, so design providing path from requirement to implementation.
In Contrast, in the OOD phase typical Question starts with "How...?"
"how will this class handle its responsibility?","How to ensure that class knows all the information it needs?","How will classes in the design communicate?". The OOD phases deals with finding conceptual solution to the problem -It is about fulfilling the requirements, but not about implementing solutions.
for example: a description of database schema and software object.
Ultimately design can be implemented, Design encompasses the discipline approach. we use to invert a solution for some problem, so design providing path from requirement to implementation.
In Contrast, in the OOD phase typical Question starts with "How...?"
"how will this class handle its responsibility?","How to ensure that class knows all the information it needs?","How will classes in the design communicate?". The OOD phases deals with finding conceptual solution to the problem -It is about fulfilling the requirements, but not about implementing solutions.
Thursday, December 29, 2016
OOA-(Introduction to OOAD)
Analysis emphasis an investigation of a problem and requirements, raaather then a solution ''Analysis is abroad term best qualified as in requirement analysis (an investigation of the requirement ) or object analysis (an investigation of the domain objects)"
In the phase of OOA the typical question start with What....? like "what will the classes in my program be?","what will be my progeam need to do?","what will each classes be responsible for?".
Hence,OOA cares about the real world and how to model this real world without getting into much detail. The OOA is an investigation of the problem and requirements, rather then finding a solution to the problem.
The primary task in OOA are:-
In the phase of OOA the typical question start with What....? like "what will the classes in my program be?","what will be my progeam need to do?","what will each classes be responsible for?".
Hence,OOA cares about the real world and how to model this real world without getting into much detail. The OOA is an investigation of the problem and requirements, rather then finding a solution to the problem.
The primary task in OOA are:-
- Identifying Objects.
- Organize object
- defining the internal of the objects (object attributes).
- defining behavior of the object (Object action).
- Describing how the object interact.
Evolution of OOAD
The object oriented paradigm took its shape from the initial concept of a new programming approach, While the method came much later.
- The first Object-Oriented Language was simula (Simulation of real systems)that was developed in 1960 by researchers at the Norwegian Computing Center.
- In 1970, Alan Kay and his research group at Xerox PARK created a personal Computer named Dynabook and the first pure object oriented programming language(OOPL)-smalltalk, for the programming the dyna book.
- In 1980s, Grady Booch Published a paper titled Object Oriented Design that mainly Presented design for the programming language,Ada.In the ensuing editions, he extended his ideas to a complete Object-Oriented design method.
- In the 1990s, coad incorporated behavioural ideas to object-Oriented method.The other significant innovations were object Modelling Techniques (OMT) by James Rumbaugh and Object-Oriented Software Engineering(OOSE) by Ivar Jacobson.
Tuesday, December 27, 2016
Database Security
7. Database Security
The data
stored in the database need to be protected from unauthorized access, malicious
destruction and alteration of data. To protect the database, we must take
security measures at several levels.
v Physical : The site or sites containing the
computer systems must be physically secured against armed or surreptitious
entry by intruders.
v Human: Users must be authorized
carefully to reduce the chance of any such user giving access to an intruder in
exchange for a bribe of other favours.
v Operating System: No matter how
secure the database system is, Weakness in operating system security may serve
as a means of unauthorized access to the database.
v Network: Since most all database
systems allow remote access through terminals or networks, software level
security within the network software is as important as physical security, both
the internet and in networks private to an enterprise.
v Database System: Some database
system users may be authorized to access only a limited portion of the database.
Other users may be allowed to issue queries, but may be forbidden to modify the
data.
7.1 SQL Access for database Security
Database Security and the DBA
The database administrator (DBA) is the central authority
for managing a database system. The DBA's responsibilities include granting
privileges to users who need to Use the system and classifying users and data
in accordance with the policy of the organization. The DBA has a DBA account in
the DBMS, sometimes called a system or superuser account, which provides
powerful capabilities that are not made available to regular database accounts
and users. DBA privileged commands include commands for granting and revoking
privileges to individual accounts, users, or user groups and for performing the
following types of actions:
1. Account creation: This action
creates a new account and password for a user or a group of users to enable
them to access the DBMS.
2. Privilege granting: This action
permits the DBA to grant certain privileges to certain accounts.
3. Privilege revocation: This
action permits the DBA to revoke (cancel) certain privileges that were
previously given to certain accounts.
4. Security level assignment: This
action consists of assigning user accounts to the appropriate security
classification level.
The DBA is responsible for the overall security of the
database system.
GRANT and REVOKE
The view mechanism allows the database to be conceptually
divided up into pieces in various ways so that sensitive information can be
hidden from unauthorized users. However, it does not allow for the
specification of the operations that authorized users are allowed to
execute against those pieces is performed by the GRANT statement.
Note first that the creator of any object is automatically
granted all privileges that make sense for that object. For example, the
creator of a base table T is automatically granted the SELECT, INSERT,
UPDATE, DELETE, and REFERENCES privileges on T
The SQL
commands used by DBA for security are as follows.
Creating
user:
Create
user supriya identified by s;
This sql
commands creates user supriya whose password is s. The privileges which can be
granted to supriya by DBA on any table employee (suppose the table employee is
already created) are SELECT,INSERT,UPDATE,DELETE,INDEX,ALTER and REFERENCE.
The
privileges can be granted by DBA to user supriya as follows.
Grant
SELECT on employee to supriya;
Similarly
INSERT,UPDATE,DELETE,INDEX,ALTER and REFERENCE can be granted to any user.
Grant all
on employee to supriya;
Grant
SELECT,UPDATE on employee to supriya;
The
REFERENCE Privilege allows the grantee to create integrity constraints that
reference that table.
Similarly the privileges can be revoked using revoke
command as follows.
Revoke all on employee from supriya;
Revoke UPDATE on employee from supriya;
The current SQL standard supports discretionary access
control only. Two more or less independent SQL features are involved-the view
mechanism, which can be used to hide
sensitive data from unauthorized users, and the authorization subsystem itself,
which allows users having specific privileges selectively and dynamically to
grant those privileges to other users, and subsequently to revoke those
privileges, if desired. Both features are discussed below.
Views and Security
To illustrate the use of views for security purposes in
SQL:
CREATE
VIEW LS AS
SELECT
S.S#, S.SNAME, S.STATUS S.CITY
FROM
S
WHERE
S,CITY = 'London'
;
The view defines the data over which authorization is to
be granted. The granting itself is done by means of the GRANT statement--e.g.:
GRANT SELECT, UPDATE , DELETE
ON LS
TO Dan, Misha ;
7.2 ACCESS CONTROL
The access to the database is controlled by defining user
to the database, assigning passwords to each user, assigning access privileges
such as read, write, delete privileges, by physical access control such as
secured entrances, password protected workstations, voice recognition
technology etc. and by using DBMS
utilities access control such as auditing and log file features. Some used
access control methods are Discretionary and Mandatory control.
Discretionary Access Control Based on Granting/Revoking of Privileges
The typical method of
enforcing discretionary access control in a database system is based on
the granting and revoking of privileges. Let us consider privileges in the
context of a relational DBMS.
Informally there are two levels for assigning privileges
to use the database system.
1.
The account level: At this level, the DBA
specifies the particular privileges that each account holds independently of
the relations in the database.
2.
The relation( or table) level: At this level, we
can control the privilege to access each individual relation or view in the
database.
The privileges at the account levels include CREATE
TABLE to create table, CREATE VIEW
to create view, CREATE
SYNONYM to create synonym and all the privileges are granted by DBA to
individual user or account.
The privileges at the relation levels include SELECT,
UPDATE, REFERENCES, DELETE for particular relations and are granted by DBA.
In SQL2, the DBA
can assign an owner to a whole, schema by creating the schema and associating
the appropriate authorization identifier with that schema using the CREATE
SCHEMA command. The owner account holder can pass privileges on any of the
owned relations to other users by granting privileges to their accounts. In SQL
the following types of privileges can be granted on each individual relation R:
n
SELECT (retrieval or read) privilege on R: Gives
the account retrieval; privilege In SQL this gives the account the privilege to use
the SELECT statement to retrieve, tuples from R.
n
MODIFY privileges on R:. This gives the account
the capability to modify tuples of R. In SQL this privilege is further divided
into UPDATE, DELETE, and INSERT Privilege to apply the corresponding SQL
command to R. In addition, both the INSERT and UPDATE privileges can specify
that only certain attributes of R can be updated by the account.
n
REFERENCES privilege on R: This gives the
account the capability to reference relation R when specifying integrity
constraints. This privilege can also be restricted to specific attributes of R.
Notice that to create a view the account must have SELECT
privilege on all the involved in the view definition.
Specifying Privileges Using Views
The mechanism of views is an important discretionary
authorization mechanism in its own right. For example, if the owner A of a
relation R wants another account B to be able to retrieve only some fields of
R, then A can create a view V of R that includes only that ' attributes and then grant SELECT on V to B.
The same applies to limiting B to retrieving only certain tuples of R; a view V
can be created by defining the view by means of a query that selects only those
tuples from R that A wants to allow B to access.
Revoking Privileges
In some cases it is desirable to grant some privilege to a
user temporarily. For example, the owner of a relation may want to grant the
SELECT privilege to a user for a specific task and then revoke that privilege
once the task is completed. Hence, a mechanism for revoking privileges is
needed. In SQL a REVOKE command is included for the purpose of canceling
privileges.
Propagation of Privileges Using the GRANT OPTION
Whenever the owner A of a relation R grants a privilege on
R to another account B, the privilege can be given to B with or without
the GRANT OPTION. If the GRANT OPTION is given, this means that B can also
grant that privilege on R to other accounts.
Specifying Limits on Propagation of Privileges
Techniques to limit the propagation of privileges have
been developed, although they have not yet been implemented in most DBMSs and
are not a part of SQL. Limiting horizontal propagation to an integer number i
means that an account B given the GRANT OPTION can grant the privilege to at
most i other accounts. Vertical propagation is more complicated; it limits the
depth of the granting of privileges. Granting a privilege with vertical
propagation of zero is equivalent to granting the privilege with no GRANT OPTION.
If account A grants a privilege to account B with vertical propagation set to
an integer number j > 0, this means that the account B has the GRANT OPTION
on that privilege, but B can grant the privilege to other accounts only with a
vertical propagation less than j. In effect, vertical propagation limits the
sequence of grant options that can be given from one account to the next based
on a single original grant of the privilege.
Mandatory Access Control for Multilevel Security
The discretionary access control technique of granting and
revoking privileges on relations has traditionally been the main security
mechanism for relational database systems. This is an all-or-nothing method: a
user either has or does not have a certain privilege. In many applications, an
additional security policy is needed that classifies data and users based on
security classes. This approach-known as mandatory access control-would typically
be combined with the discretionary access control mechanisms. It is important
to note that most commercial DBMSs currently provide mechanisms only for
discretionary access control. However, the need for multilevel security exists
in government, military, and intelligence applications, as well as in many
industrial and corporate application.
Typical security classes are top secret (TS), secret (S),
confidential (C), and unclassified (U), where TS is the highest level and U
the lowest Other more complex security classification schemes exist, in which
the security classes are organized in a lattice. For simplicity, four security classification levels, where TS
³
S ³
C ³
U are used in the system. The commonly used model for multilevel security known
as the Bell-LaPadula model, classifies each subject (user, account, program)
and object (relation, tuple, column, view, operation) into one of the security
classifications TS, S, C, or U. We will refer to the clearance (classification)
of a subject S as class (S) and to the classification of an object O as class
(O). Two restrictions are enforced on data access based on the subject/object
classifications: '
1. A
subject S is not allowed read access to an object O unless class(S) ³
class(O).
This
is known as the simple security property.
2. A subject S is not allowed to write an
object O unless class(S) £ class(O). This is, known as the *property (or star
property).
The first restriction is intuitive and enforces the
obvious rule that no subject can read an object whose security classification
is higher than the subject's security clearance. The second restriction is less
intuitive. It prohibits a subject from writing an object at a lower security
classification than the subject's security clearance. Violation of this rule
would allow information to flow from higher to lower classifications, which violates
a basic tenet of multilevel security. For example, a user (subject) with TS
clearance may make a copy' of an object with classification TS and then write
it back as a new object with classification U,
thus making it visible throughout the system.
To incorporate multilevel security notions into the
relational database model, it is common to consider attribute values and tuples
as data objects. Hence, each attribute A is associated with a classification
attribute C in the schema, and each attribute value in a tuple is associated
with a corresponding security classification,- In addition, in some models, a
tuple classification attribute TC is added to the relation attributes to
provide a classification for each tuple as a whole. Hence, a multilevel relation
schema R with n attributes would be represented as
R(A1, C1, A2, C2,
..., An, Cn, TC)
where each Ci
represents the classification attribute associated with attribute Ai.
The value of the TC attribute in each tuple t-which is the
highest of all attribute classification values within t-provides a general
classification for the tuple itself, whereas each ci provides a
finer security classification for each attribute value within the tuple. The
apparent key of a multilevel relation is the set of attributes that would have
formed the primary key in a regular (single-level) relation. A multilevel
relation will appear to contain different data to subjects (users) with
different clearance levels. In some cases, it is possible to store a single
tuple in the relation at a higher classification level and produce the
corresponding tuples at a lower level classification through a process known as
filtering. In other cases, it is necessary to store two or more tuples at
different classification levels with the same value for the apparent key, This
leads to the concept of polyinstantiation, where several tuples can have the
same apparent key value but have different attribute values for users at
different classification levels.
Assume that the Name attribute is the apparent key, and
consider the query SELECT * FROM
EMPLOYEE. A user with security clearance S would see the same relation shown
below in fig.a, since all tuple classifications are less than or equal to S.
However a user with security clearance C would not be allowed to see values for
salary of Shyam and job performance for Ram as shown below in fig. b .
a.
EMPLOYEE
Name Salary JobPerformance TC
Ram U 5000 C Fair S S
Shyam C 5000 S Good C S
Fig.
The original Employee tuples
b.
EMPLOYEE
Name Salary JobPerformance TC
Ram U 5000 C Null C C
Shyam C null C Good C C
Fig.
Appearance of EMPLOYEE after filtering for classification C users
7.3 ENCRYPTION
Access control is only applied to the established avenues
of access to the database. Clever people using clever instruments may be able
to access the data by circumventing the controlled avenues of access. Also,
innocent people who passively stumble upon an avenue of access may be unable to
resist the temptation 'to look at and pet misuse the data so acquired. To
counteract the possibility that either active or passive intruders obtain
unauthorized access to sensitive data, it is desirable to obscure or hide the
meaning of the data accessed.
Encryption is any sort of transformation applied to
data (or text) prior to transmission or prior to storage, which makes it more
difficult to extract information content or meaning. Decryption is method of
retrieving the original message(text) from the encrypted message. The word
'cryptography' comes from the Greek meaning 'hidden or secret. Cryptography
includes both encryption and decryption.
Encryption techniques complement access controls. Access
controls are ineffective if
n
A user leaves a listing in the work area or in
the trash.
n
Passwords are written down and found.
n
Offline backup files are stolen.
n
Confidential data is left in main memory after a
job has completed.
n
Someone taps in on a communication line.
When a data system' is geographically dispersed, physical
security measures be come less practical and less effective against intrusion
because the system is more open and
vulnerable to penetration at more points. If the computer system and all the
sensitive data are maintained in a single, isolated environment into
which a user must be admitted before
access to data is permitted, little need for encryption exists. An increased
need for encryption comes with the increased tendency for systems to reach out
into the using environment and become 'more available to the users.
The basic encryption
scheme is shown in Figure . Original plaintext is transformed by an encryption
algorithm using an encryption key to produce ciphertext. An
inverse decryption algorithm transforms the ciphertext using the same
(or related) key to reconstruct the plaintext.
Figure Basic Encryption/ Decryption System.
An encryption algorithm (T). transforms a sender's
plaintext message (M) using a key (K) to produce ciphertext. Plaintext'is in a
form recognizable by humans (or computers). The encrypted message or data can
be transmitted through an insecure channel or stored in an insecure area since
a potential intruder would only see a
scrambled message. Using the same (or related) key, the decryption algorithm
applies an in years transformation (T-1) to the ciphertext to
reconstruct the original message (M). Transmission of the key to the decryption
must be kept secure, since knowing the decryption key and the encryption
algorithm makes it easy to decrypt or decipher a message, thereby disclosing
sensitive information.
In a database environment, encryption techniques can be
applied to:
n
Transmitted data sent over communication lines
between computer systems, or to and from remote terminals (1).
n
Stored data:
Ü remote
backup data on removable media (2)
Ü active
data on secondary storage devices (3)
Ü tables
and buffers in internal main memory (4)
The figure below indicates the points where encryption can
be used to protect data from unauthorized access during transmission between
the user and the system. With a remote database, encryption can be used to
protect the stored data from unauthorized access.
Fig Encryption in a
Database Environment.
Encryption
techniques can be used in the transmission or storage of data. The stored data
may be remote backup data on removable media, active (updated) data on
secondary storage devices, or tables and buffers in internal memory. Sensitive
data outside of secured area is more exposed to unauthorized disclosure and
therefore encryption can contribute significantly to greater security.
Encryption methods can be classified according to:
1. The nature of the algorithm:
n
Transposition, or permutation in general.
n
Substitution, either mono-alphabetic or
polyalphabetic.
n
Product, combining permutations and
substitutions.
Cryptographic techniques have been widely used in military
and government intelligence activities for centuries but due to the secretive
nature of the subject.
The increased potential for more sophisticated encryption
and cryptanalysis through the use of computers, coupled with the increased
concern for data privacy, has generated a great surge of interest in the past
decade or two. There has been substantial published literature on the use of
encryption in computerized database systems. The U:S. Government has adopted a
data encryption standard(DES).
Choosing an
encryption method depends upon the cost, what is available, and the level of
user need. The object of any particular method is to raise the work factor high
enough to discourage anyone from breaking the code. The cost of the chosen
method must be commensurate with the level of risk and the degree of security
desired. Even fairly modest and simple encryption methods can render
transmitted messages and stored data secure from all but the most persistent
penetrators.
Traditional Methods: Transposition and Substitution
Historically, transposition and substitution have been the
two major classes of encryption techniques. They were applied manually to
encrypt streams of text prior to transmission. Permutations and substitutions
serve as the basis for some present-day computerized methods.
Transposition techniques permute the ordering of
characters in the data stream according to some rule. For example, if the
transposition pattern or rule is to transpose each consecutive pair of
characters, the phrase
database
would appear as
ADATABES
obviously not very secure. An example of a general
permutation would be to form blocks of, say, four characters and permute, 1234
to 3124. The phrase would now appear as:
TDAASBAE
With a correct guess of the length of the permutation
block, only a few trials are needed to break the code.
Substitution techniques retain the relative position of
the characters in the original plaintext but hide their identity in the
ciphertext. By contrast, transposition techniques retain the identity of the
original characters but change their position.
A simple example is the Caesar Cipher which
substitutes the nth letter away from ..the plaintext character in the alphabet.
This is applied 'modulo 27' (includes a blank), that is, if you count past the
end of the alphabet, cycle back to the beginning. The plaintext message in Fig.
was encrypted using a Caesar Cipher. The n is the key indicating the alphabet
shift.
A general mono-alphabetic substitution cipher replaces
characters in the plaintext with characters from some other alphabet, called a
cipher alphabet, which becomes the key. For example:
Plaintext alphabet: abcdefghijklmnopqrstuvwxyz
Ciphertext alphabet: GORDNCHALESZYXWVUTQPMKJIFB
Transforms the
Plaintext: database management
system
Into the Ciphertext: DGPGOGQN YGXGHNYNXP
QFQPNYQ
Assuming that the plaintext message is written in natural
English using 26 letters, mono-alphabetic substutions are susceptible to
frequency analysis of single letters, letter pairs, and reversals. The
analysis is increasingly accurate for larger messages the letter frequencies
in the message would approach the 'characteristic letter frequencies for the
language. In English the most frequently occurring letters are
E,T,A,O,N,R,I,S,H. Some people can' even read such ciphertext directly Some computers
have built-in machine instructions to perform substitutions between two alphabets
(needed for A_CII-EBCDI_ code conversion), thus enabling faster exhaustive
analysis of mono-alphabetic' substitutions.
Polyalphabetic substitution uses multiple alphabets
cyclically according to some rule. Each character of the plaintext is replaced'
with a character from a different Ciphertext alphabet, thereby obscuring the
frequency characteristics of the characters in the plaintext alphabet.
Concurrency control
Transaction
Collections of operations that form a single logical unit
of work are called transactions. for example, a transfer of funds from a
checking account to a savings account is a single operation when viewed from
the customer's standpoint; within the database system, however, it comprises
several operation. Clearly, it is essential that all these operation occur, or
that, in case of a failure, none occur. It would be unacceptable if the
checking account were debited, but the savings account were not credited. A
database system must ensure proper execution of transactions despite failures-
either the entire transaction executes, or none of it does.
A transaction is a unit of program execution that accesses
and possible updates various data items. A collection of operations that should
be treated as a single logical operation. A transaction usually results from
the execution of a user program and the in the program the transaction is of
the form begin transaction and end transaction .
To ensure integrity of data, we require that the database
system maintains the following properties (called ACID properties)of the
transactions.
ACID (Atomicity, Consistency, Isolation, Durability)
The four states defined by the acronym ACID (atomicity,
consistency, isolation, and durability) relate to a successful transaction,
usually a database transaction. All of these characteristics must be present,
or the transaction must be completely reversed (undone or rolled back).
A: Atomicity: either the entire set of
operations happens or none of it does. Atomicity refers to the ability
of the DBMS to guarantee that either all of the tasks of a transaction are
performed or none of them are. The transfer of funds can be completed or it can
fail for a multitude of reasons, but atomicity guarantees that one account
won't be debited if the other is not credited as well.
C:
Consistency: the
set of operations taken together should move the system from one consistent
state to another. Consistency refers to the database being in a legal
state when the transaction begins and when it ends. This means that a
transaction can't break the rules, or integrity constraints,
of the database. If an integrity constraint states that all accounts must have
a positive balance, then any transaction violating this rule will be aborted.
I: Isolation: even though multiple transactions may
operate concurrently, there is a total order on all transactions. Stated
another way: each transaction perceives the system as if no other transactions
were running concurrently. Isolation
refers to the ability of the application to make operations in a transaction
appear isolated from all other operations. This means that no operation outside
the transaction can ever see the data in an intermediate state; a bank manager can
see the transferred funds on one account or the other, but never on both --
even if he ran his query while the transfer was still being processed.
D: Durability: even in the face of a crash, once
the system has said that a transaction completed, the results of the
transaction must be permanent. Durability
refers to the guarantee that once the user has been notified of success, the
transaction will persist, and not be undone. This means it will survive system
failure, and that the database system has checked the integrity constraints and won't need to abort the
transaction. Typically, all transactions are written into a log that can be played back to recreate the
system to the its state right before the failure. A transaction can only
be deemed committed after it is safely in the log. Implementing
the ACID properties correctly is not simple. Processing a transaction often
requires a number of small changes to be made, including updating indexes that
are used by the system to speed up searches. This sequence of operations is
subject to failure for a number of reasons; for instance, the system may have
no room left on its disk drives. ACID suggests that the database be able to
perform all of these operations at once. In fact this is difficult to arrange.
There are two popular families of techniques: Write ahead logging and Shadow
paging. In both cases, locks must be acquired on all information that is read
and updated. In write ahead logging, atomicity is guaranteed by ensuring that
all REDO and UNDO information is written to a log before it is written to the
database. In shadowing, updates are applied to a copy of the database, and the
new copy is activated when the transaction commits. The copy refers to
unchanged parts of the old version of the database, rather than being an entire
duplicate.
Terminology
Concurrency control: the method of ensuring that
simultaneously running transactions provide isolation.
Recovery: the act of taking a database after an
unexpected failure and returning it to a consistent state.
Abort: undo a transaction.
Commit: make
a transaction permanent.
Rollback: the act of "undoing" a
transaction.
Transaction manager or transaction monitor: the
component responsible for maintaining the ACID properties.
Compensating transaction: a transaction used to
undo (rollback) another transaction.
Unresolved transaction: a transaction that has
neither aborted nor committed.
Terminated transaction: a transaction that has
either aborted or committed.
The Life and Times of a Transaction
n
Transactions begin by some sort of
"transaction begin" operation.
n
Transactions end either by being committed or
aborted.
n
Abort: return the system to the state it was in
before the transaction began.
Ü System
state must be the same as if the transaction had never existed.
Ü Must
abort any transactions that depend on the outcome of the aborting transaction.
n
Commit: declare the transaction permanently
complete.
Ü If
you say you've committed, no actions should be able to move the system to a
state not containing the transaction.
Ü All
operations much be forever persistent in the database.
Transaction States
Active: initial state. Entered upon begin; stays in this
state while running.
n
Partially Committed: All statements in the
transaction have been completed.
n
Failed: The transaction has encountered an
abnormal or errant condition and cannot continue.
n
Committed: The transaction is complete and can
never be undone.
n
Aborted: The system has been returned to its
pre-transaction state.
Three concurrency problems
There are essentially three ways in which things can go
wrong three ways, that is, in which a transaction, through correct in itself,
can nevertheless produce the wrong answer if some other transaction interferes
with it in some way. It should be noted that the interfering transaction might
also be correct in itself; it is the uncontrolled interleaving of operations
from the two correct transactions that produces the overall incorrect result.
The three-concurrency problems are:
n
The lost update problem;
n
The uncommitted dependency problem and
n
The inconsistent analysis problem
The Lost Update Problem
Consider the situation illustrated in Fig. That figure is
meant to be read as follows: Transaction A retrieves some tuple to at time t1;
transaction B retrieves that same tuple t at
|
Transaction A
|
Time
|
Transaction B
|
|
-
|
|
|
-
|
|
-
|
|
|
-
|
|
RETRIEVE t
|
t1
|
-
|
|
-
|
|
|
-
|
|
-
|
t2
|
RETRIEVE t
|
|
-
|
|
|
-
|
|
UPDATE t
|
t3
|
-
|
|
-
|
|
|
-
|
|
-
|
t4
|
UPDATE t
|
|
-
|
¯
|
-
|
Transaction A loses an update at time t4
Time t2; transaction A updates the tuple (on the basis of
the values seen at time t1) at time t3; and transaction B updates the same
tuple (on the basis of the values seen at time t2 which are the same as those
seen at time t1) at time t4. Transaction A’s update is lost at time t4, because
transaction B overwrites it without even looking at it.
The Uncommitted Dependency Problem
The uncommitted dependency problem arises if one
transaction is allowed to retrieve or, worse, update – a tuple that has been updated
by another transaction but not yet committed by that other transaction. For if
it has not yet been committed, there is always a possibility that it never will
be committed but will be rolled back instead
In the first example (Fig), transaction A seen an
uncommitted update (also called an uncommitted change) at time t2. That update
is then undone at time t3. Transaction A is
|
Transaction A
|
Time
|
Transaction B
|
|
-
|
|
|
-
|
|
-
|
|
|
-
|
|
-
|
t1
|
UPDATE t
|
|
-
|
|
|
-
|
|
RETRIEVE t
|
t2
|
-
|
|
-
|
|
|
-
|
|
-
|
t3
|
ROLLBACK
|
|
-
|
¯
|
|
Transaction A becomes dependent on an uncommitted change at
time t2
|
Transaction A
|
Time
|
Transaction B
|
|
-
|
|
|
-
|
|
-
|
|
|
-
|
|
-
|
t1
|
UPDATE t
|
|
-
|
|
|
-
|
|
UPDATE t
|
t2
|
-
|
|
-
|
|
|
-
|
|
-
|
t3
|
ROLLBACK
|
|
-
|
¯
|
|
Transaction A updates an uncommitted change at time t2, and
loses that update at update at time t3
therefore
operating on a false assumption-namely, the assumption that tuple t has the
value seen at time t2, whereas in fact it has whatever value it had prior to
time t1. As a result, transaction A might well produce incorrect output. Now, by
the way that the rollback of transaction B might be due to no fault of B’s –it
might, for example be the result of a system crash. (And transaction A might
already have terminated by that time, in which case the crash would not cause a
rollback to be issued for A also.)
The second example
is even worse. Not only does transaction A become dependent on a
uncommitted change at time t2, but it actually loses an update at time
t3-because the rollback at time r3 cause tuple t to be restored to its value
prior to time t1. This is another version of the lost update problem.
The Inconsistent Analysis Problem
Consider Fig , which shows two transactions A and B
operating on account (ACC) tuples: Transaction A is summing account balance;
transaction B is transferring an amount 10 from account 3 to account 1. The
result produced by A 110, is obviously incorrect; if A were to go on the write
that result back into the database, it would actually
|
|
ACC
3
|
||||||||
Transaction A
|
Time
|
Transaction B
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
|
|
-
|
||||||||
|
RETRIEVE ACC 1 :
|
t1
|
-
|
||||||||
|
sum = 40
|
|
|
-
|
||||||||
|
-
|
|
|
-
|
||||||||
|
RETRIEVE ACC 2 :
|
t2
|
-
|
||||||||
|
sum = 90
|
|
|
-
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t3
|
RETRIEVE ACC 3
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t4
|
UPDATE ACC 3 :
|
||||||||
|
-
|
|
|
30 ®
20
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t5
|
RETRIEVE ACC 1
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t6
|
UPDATE ACC 1
|
||||||||
|
-
|
|
|
40 ®
50
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t7
|
COMMIT
|
||||||||
|
-
|
|
|
|
||||||||
|
RETRIVE ACC 3 :
|
t8
|
|
||||||||
|
sum = 110, not 120
|
|
|
|
||||||||
|
-
|
¯
|
|
Transaction A performs as inconsistent analysis
leave the database in inconsistent state. We say that A
has seen an inconsistent state of the database and has therefore performed an
inconsistent analysis. Note the difference between this example and the
previous one: There is no question here of A being dependent on an uncommitted
change, since B commits all of its updates before A see ACC3.
Locking
Concurrency problems can all be solved by means of a
concurrency control technique called locking. The basic idea is simple: When a
transaction needs an assurance that some object it is interested in typically a
database tuple–will not change in some manner while its back is turned (as it
were), it acquires a lock on the object. The effect of the lock is to “lock
other transaction of the object in question, and thus in particular to prevent
them from changing it. The first transaction is therefore able to carry out its
processing in the certain knowledge that the object in question will remain in
a stable state for al long as the transaction wishes it to.
The working of locks can be explained as follows.
1. First, we assume the system supports
two kinds of locks, exclusive locks (X locks) and shared locks (S locks). Note:
X and S locks are sometimes called write locks and read locks, respectively.
2. If transaction A holds an exclusive (X)
lock on tuple t, then a request from some distinct transaction B for a lock of
either type on t will be denied.
3. If transaction A holds a shared (S)
lock on tuple t, then:
n
A request from some distinct transaction B for
an X lock on t will be denied;
n
A request from some distinct transaction B for
an S lock on t will be granted (that is, B will now also hold an S lock on t).
These rules can conveniently be summarized by means of a
lock type compatibility matrix (As shown in fig). That matrix is interpreted as
follows: Consider some tuple t; suppose transaction A currently holds a lock on
t as indicated by the entries in the column headings (dash=no lock); and
suppose some distinct transaction B issues a request for a lock on t as
indicated by the entries down the left-hand side (for completeness we again
include the “no lock” case). An “N” indicates a conflict (B's request cannot be
satisfied and B goes into a wait state), a “Y” indicates compatibility (B's
request is satisfied). The matrix is obviously symmetric.
|
|
X
|
S
|
-
|
|
X
|
N
|
N
|
Y
|
|
S
|
N
|
Y
|
Y
|
|
-
|
Y
|
Y
|
Y
|
Compatibility matrix for lock types X and S.
data access protocol (or locking protocol) that makes use
of X and S locks as just defined to guarantee that problems cannot occur.
1. A
transaction that wishes to retrieve a tuple must first acquire an S lock on
that tuple.
2. A transaction that wishes to update a
tuple must first acquire an X lock on that tuple. Alternatively, if it already
holds an S lock on the tuple (as it will in a RETRIEE-UPDATE sequence), then it
must promote that S lock to X level.
It should be noted that transaction requests for tuple
locks are normally implicit; a “tuple retrieve” request is an implicit request
for an S lock, and a “tuple update” request is an implicit request for an X
lock, on the relevant tuple. Also, of course (as always), we take the term
“update” to include INSERT and DELETEs as well as UPDATEs per se, but the rules
requires some minor refinement to take care of INSERTs and DELETEs.
To continue with the protocol:
3. If a lock request from transaction B is
denied because it conflicts with a lock already held by transaction A,
transaction B goes into a wait state. B will wait until A's lock is released.
Note: The system must guarantee that B does not wait forever (a possibility
sometimes referred to as livelock). A simple way to provide such a guarantee is
to service all lock request on a “first-come, first-served” basis.
4. X locks are held until
end-of-transaction (COMMIT or ROLLBACK).
The Three Concurrency Problems Protocols
The Lost Update Problem
As shown in fig, Transaction A's UPDATE at time t3 is not
accepted, because it is an implicit request for an X lock on t, and such a
request conflicts with the S lock already held by transaction B; so A goes into
a wait state. For analogous reasons, B goes into a wait state at time t4. Now
both transactions are unable to proceed, so there is no question of any update
being lost. Locking thus solves the lost update problem by reducing it to
another problem!-but at least it does solve the original problem.
|
Transaction A
|
Time
|
Transaction B
|
|
-
|
|
|
-
|
|
-
|
|
|
-
|
|
RETRIEVE ACC 1 :
|
t1
|
-
|
|
(acquire s lock on to)
|
|
|
-
|
|
-
|
|
|
-
|
|
-
|
t2
|
RETRIEVE t
|
|
-
|
|
|
(acquire S lock on t)
|
|
-
|
|
|
-
|
|
UPDATE t
|
t3
|
-
|
|
(request X lock on t)
|
|
|
-
|
|
wait
|
|
|
-
|
|
wait
|
t4
|
UPDATE t
|
|
wait
|
|
|
(request X lock on t)
|
|
wait
|
|
|
wait
|
|
wait
|
|
|
wait
|
|
wait
|
¯
|
wait
|
No update is lost, but deadlock occurs at time t4
The Uncommitted Dependency Problem
As shown in fig. Transaction A's operation at time t2
(RETRIEVE and UPDATE in Fig.) is not accepted in either case, because it is an
implicit request for a lock on t, and such a request conflicts with the X lock
already held by B; so A goes into a wait state. It remains in that wait state
until B reaches its termination (either COMMIT or ROLLBACK), when B's lock is
released and A is able to proceed; and at that point A sees a committed value
(either the pre-B value, if B terminates with rollback, or the post-B value
otherwise). Either way, A is no longer dependent on an uncommitted update.
|
Transaction A
|
Time
|
Transaction B
|
|
-
|
|
|
-
|
|
-
|
|
|
-
|
|
-
|
t1
|
UPDATE t
|
|
-
|
|
|
(acquire X lock on t)
|
|
-
|
|
|
-
|
|
RETRIEVE t
|
t2
|
-
|
|
(request S lock on t)
|
|
|
-
|
|
wait
|
|
|
-
|
|
wait
|
t3
|
COMMIT / ROLLBACK
|
|
wait
|
|
|
(release X lock on t)
|
|
resume : RETRIEVE t
|
t4
|
|
|
(acquire S lock on t)
|
|
|
|
|
-
|
¯
|
|
Transaction A is prevented from seeing an uncommitted
change at time t2
|
Transaction A
|
Time
|
Transaction B
|
|
-
|
|
|
-
|
|
-
|
|
|
-
|
|
-
|
t1
|
UPDATE t
|
|
-
|
|
|
(acquire X lock on t)
|
|
-
|
|
|
-
|
|
RETRIEVE t
|
t2
|
-
|
|
(request S lock on t)
|
|
|
-
|
|
wait
|
|
|
-
|
|
wait
|
t3
|
COMMIT / ROLLBACK
|
|
wait
|
|
|
(release X lock on t)
|
|
resume : RETRIEVE t
|
t4
|
|
|
(acquire S lock on t)
|
|
|
|
|
-
|
¯
|
|
Transaction A is prevented from updating an uncommitted
change at time t2
The Inconsistent Analysis Problem
As shown in fig., Transaction B's UPDATE at time t6 is not
accepted, because it is an implicit request for an X lock an ACC 1, and such a
request conflicts with the S lock already held by A; so B goes into a wait
state. Likewise, transaction A's RETREIVE at time t7 is also not accepted,
because it is an implicit request for an S lock an ACC 3, and such a request
conflicts with the X lock already by B; so A goes into a wait state also.
Again, therefore, locking solves the original problem (the inconsistent
analysis problem, in this case) by forcing a deadlock.
|
|
ACC
3
|
||||||||
Transaction A
|
Time
|
Transaction B
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
|
|
-
|
||||||||
|
RETRIEVE ACC 1 :
|
t1
|
-
|
||||||||
|
(acquire S lock on ACC 1)
|
|
|
-
|
||||||||
|
Sum = 40
|
|
|
-
|
||||||||
|
-
|
|
|
-
|
||||||||
|
RETRIEVE ACC 2 :
|
t2
|
-
|
||||||||
|
(acquire S lock on ACC 2)
|
|
|
-
|
||||||||
|
sum = 90
|
|
|
-
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t3
|
RETRIEVE ACC 3
|
||||||||
|
-
|
|
|
(acquire X lock on ACC 3)
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t4
|
UPDATE ACC 3
|
||||||||
|
|
|
|
(acquire X lock on ACC 3)
|
||||||||
|
-
|
|
|
30 ®
20
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t5
|
RETRIEVE ACC 1
|
||||||||
|
-
|
|
|
(acquire S lock on ACC 1)
|
||||||||
|
-
|
|
|
-
|
||||||||
|
-
|
t6
|
UPDATE ACC 1
|
||||||||
|
-
|
|
|
(request X lock on ACC 3)
|
||||||||
|
-
|
|
|
wait
|
||||||||
|
RETRIEVE ACC 3 :
|
t7
|
wait
|
||||||||
|
(request S lock on ACC 3)
|
|
|
wait
|
||||||||
|
wait
|
|
|
wait
|
||||||||
|
wait
|
¯
|
wait
|
Inconsistent analysis is prevented, but deadlock occurs at
time t7
Deadlock Handling
A system is in a deadlock state if there exists a set of
transactions such that every transaction in the set is waiting for another
transaction in the set. More precisely, there exists a set of waiting
transaction {TO,T1,…,Tn} such that TO
is waiting for a data item that is held by T1, and T1 is
waiting for a data item that is held by T2 , and.., and Tn-1
is waiting for a data item that is held by Tn, and Tn is
waiting for a data item that is held by TO. None of the transactions
can make progress in such a situation.
n
Occurs when two or more transactions are blocked
waiting on each other in such a manner that none will make forward progress.
n
Two approaches
Ü Prevention:
do not let deadlocks occur.
Ü Detection
and Recovery: allow deadlocks to occur, but detect it and do something about
it.
Deadlock Prevention
n
Three categories
Ü Order
lock requests in such a way that deadlock can never occur.
Ü Abort
a transaction instead of waiting when there is the potential for deadlock.
Ü Use
time-outs.
n
Lock ordering
Ü Simple
scheme: request all locks atomically at once.
Difficult to know what to lock at the beginning of the
transaction.
May hold items locked for along time unnecessarily.
n
Preemptive schemes
Ü Assign
a timestamp to each transaction when it begins.
Ü At
the time a transaction is about to wait, decide if we allow the transaction to
wait, force it to abort, or force someone else to abort.
Ü If
a transaction aborts, we do not give it a new timestamp.
Ü wait-die:
wait only on younger transactions; if you encounter an older transaction, abort
self.
Ü wound-die:
if transaction would block on a younger transaction, abort the younger
transaction (i.e., wound it).
Ü Trade-offs
wait-die: older transactions wait more (but eventually
finish).
wait-die: a transaction might get aborted several times
before it finally completes.
1. wound-wait:
may be fewer rollbacks than wait-die.
Ü Both
schemes do a lot of rollbacks that may not be necessary.
n
Time-out based schemes
Ü Allow
a transaction to wait for at most a specified time.
Ü If
the time elapses, the transaction rolls back.
Deadlock Detection and Recovery
n
Construct/maintain a waits-for graph.
Ü Vertex
set consists of all transactions.
Ü An
edge from Vi to V j indicates that T
i is waiting on a lock held by T
j .
n
If there is a cycle in the graph, then a
deadlock exists.
n
Pick a participant in the deadlock and abort it.
Ü May
be possible to do partial rollback (i.e., only roll back far enough to break
the deadlock instead of to the beginning of the transaction).
Ü In
practice, far too complex to maintain the state necessary to do this.
Ü Avoid
starvation: do not want the same transaction continually getting rolled back.
Can select a policy that favors transactions previously
aborted.
Buffer Management
Programs in a database system make requests on the buffer
manager when they need a block from disk. If the block is already in the
buffer, the requester is passed the address of the block in main memory. If the
block is not in the buffer, the buffer manager first allocates space in the
buffer for the block, throwing out some other block, if required, to make space
for the new block. The block that is thrown out is written back to disk only if
it was modified since the most recent time that it was written to the disk.
Then, the buffer manager reads in the block from the disk to the buffer, and
passes the address of the block in main memory to the requester. The internal
actions of the buffer manager are transparent to the programs that issue disk-
block requests.
Buffer manager appears to be nothing more than a virtual
memory manager, like those found in most operating systems. One difference is
that the size of memory addresses are not sufficient to address all disks
blocks. Further, to serve the database system well, the buffer manager must use
techniques more sophisticated than typical virtual memory management schemes.
Replacement strategy: When there is no room left in the
buffer, a block must be removed from the buffer before a new one can read in.
Typically, operating systems use a least recently used(LRU) scheme, in which
the block that was referenced least recently is written back to disk and is
removed from the buffer. This simple approach can be improved on for database
applications.
Pined blocks: For the database system to be able to
recover from crashes it is necessary to restrict those times when a block may
be written back to disk. A block that is not allowed to be written back to disk
is said to be pined. Although many operating systems do not provide support for
pinned blocks, such a feature is essential for the implementation of a database
system that is resilient to crashes.
Forced output of blocks: There are situations in which it
is necessary to write back the block to disk, even thought the buffer space
that is occupies is not needed. This write is call the forced output of a
block Main memory contents and thus
buffer contents are lost in a crash, whereas data on disk usually survive a
crash.
Subscribe to:
Comments (Atom)
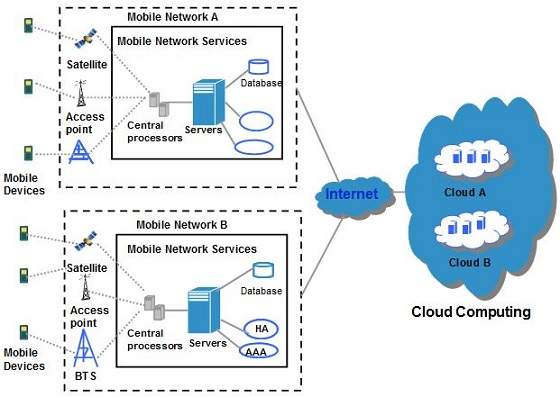
Mobile Cloud Computing
Cloud Computing offers such smartphones that have rich Internet media support, require less processing and consume less power. In terms of ...
-
It refers to a type of Computer Programming in which Programmers define not only the data type of data structure, but also the type of Opera...
-
Cloud Security Challenges: Software as a Service Security: The seven security issues which one should discuss with a cloud-computin...
-
Cloud Computing offers such smartphones that have rich Internet media support, require less processing and consume less power. In terms of ...
